*3 http://www.juce.com
*4 released by Flux: company http://www.ircamtools.com
*3 http://www.juce.com
*4 released by Flux: company http://www.ircamtools.com
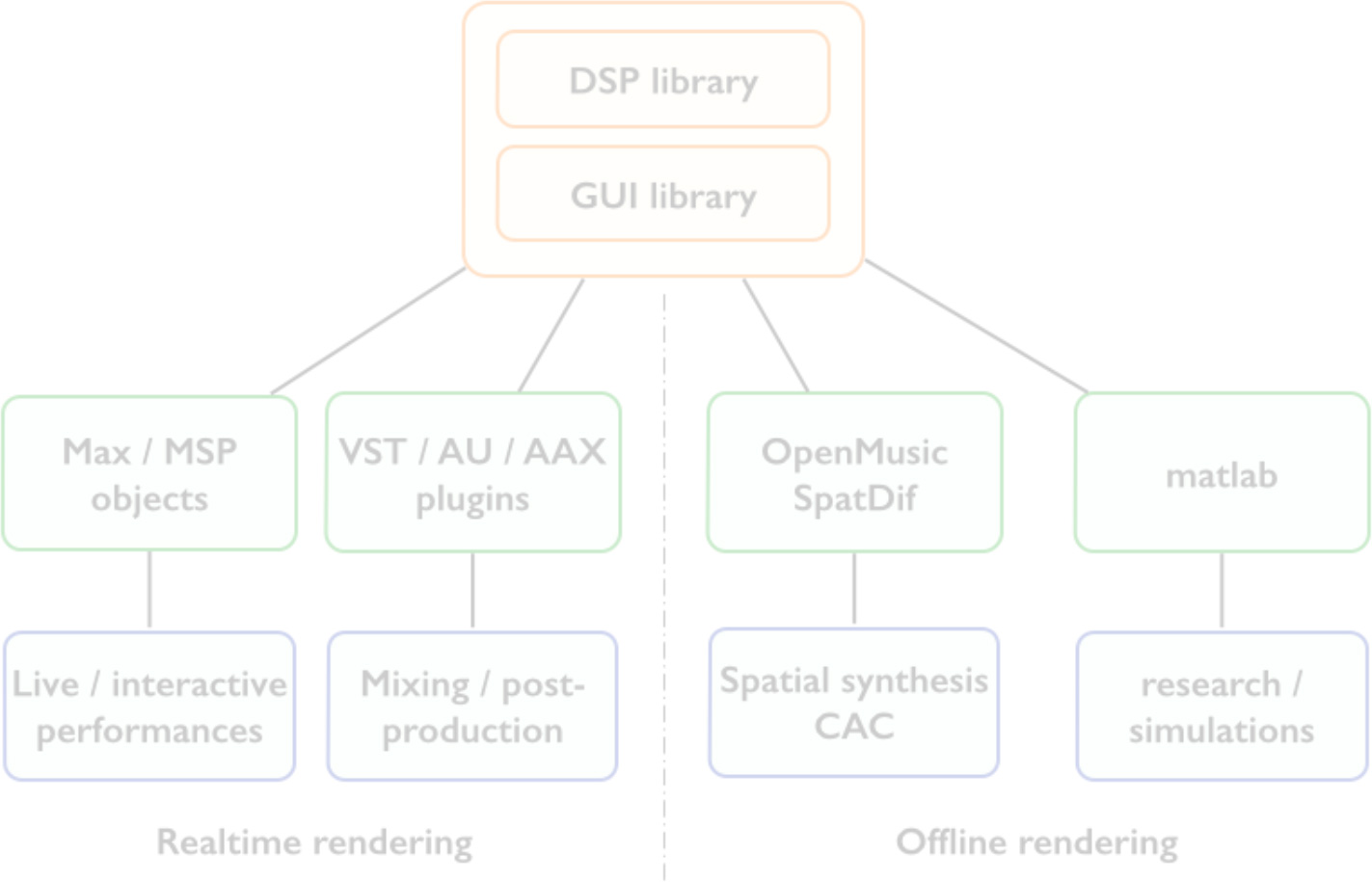
Figure 1. Spatialisateur bindings in various working environments.
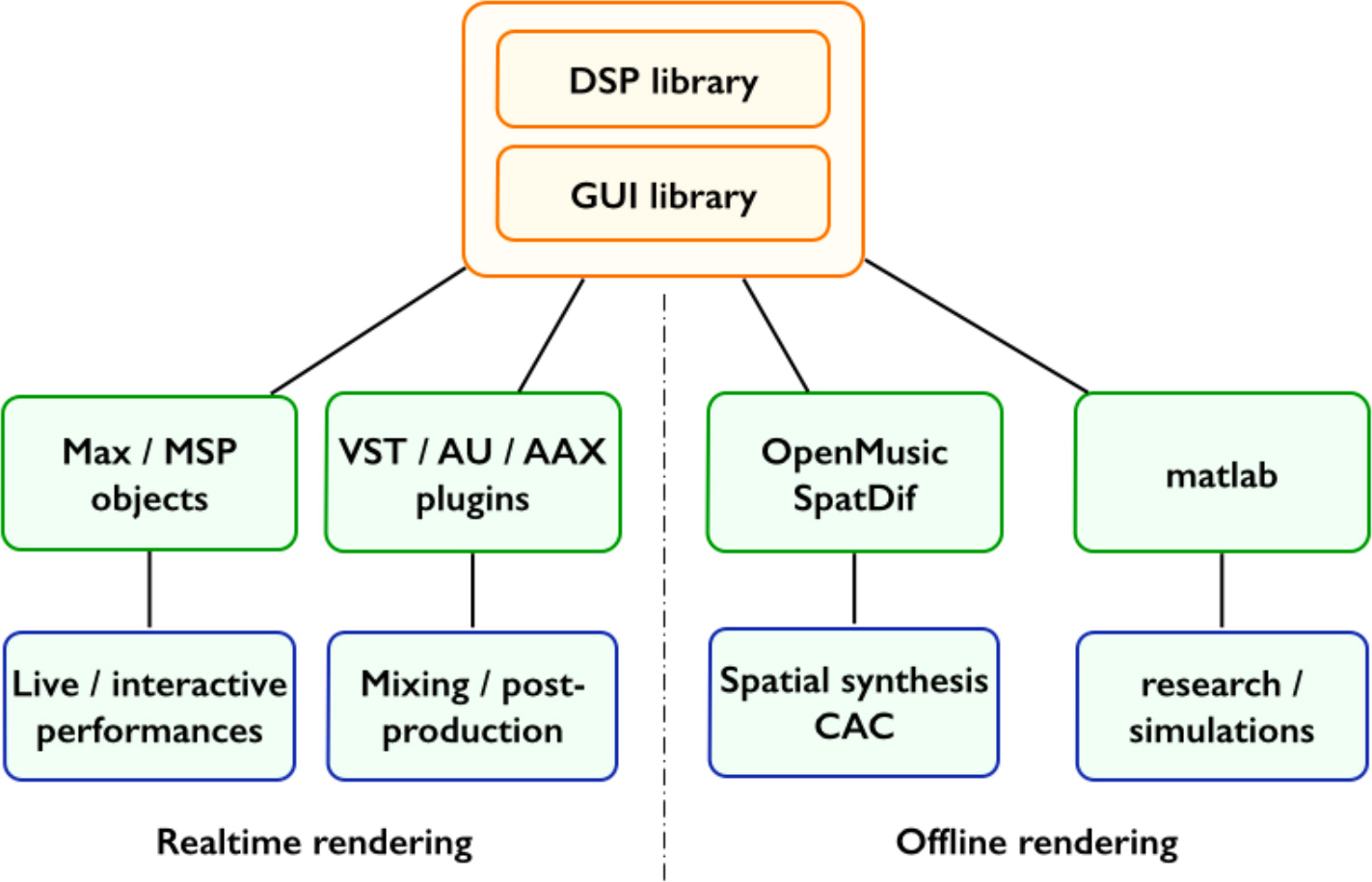
図1.様々な作業環境でバインディングされるSpatialisateur
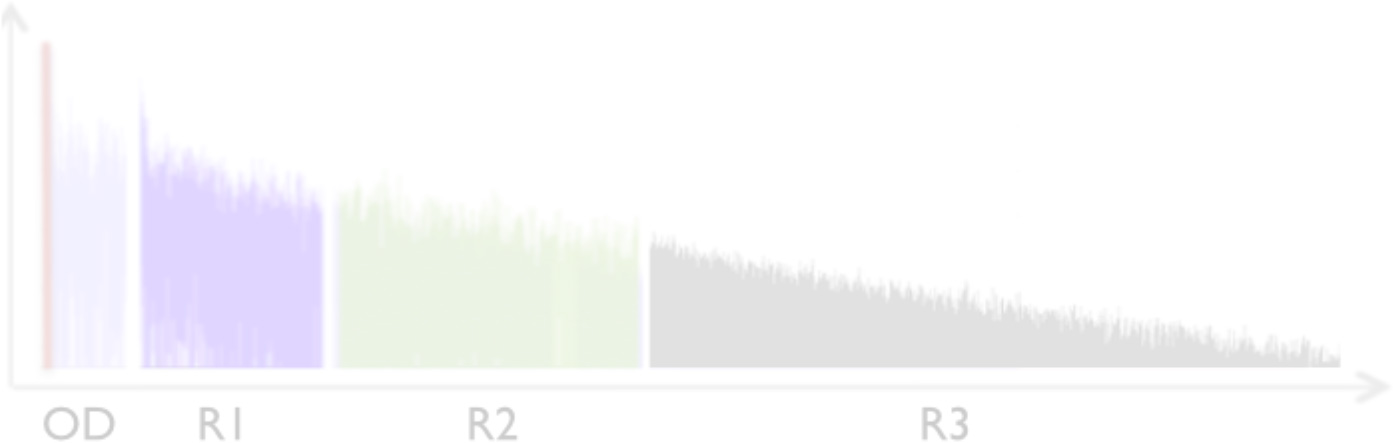
Figure 2. Archetype of an impulse response generated by the Spatialisateur reverberation engine.
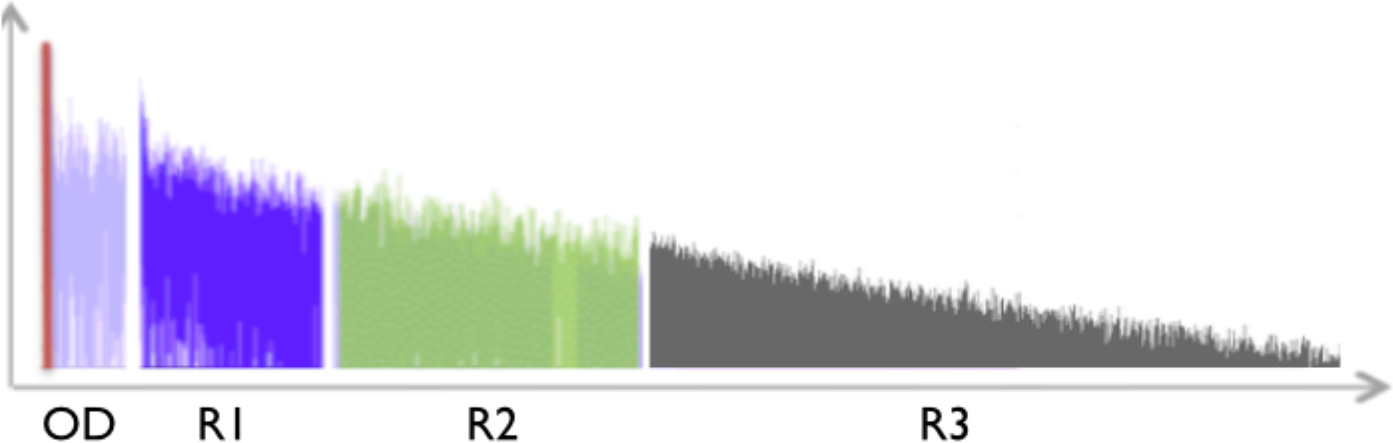
図2.Spatialisateurのリバーブ・エンジンが生成するインパルス応答の典型。
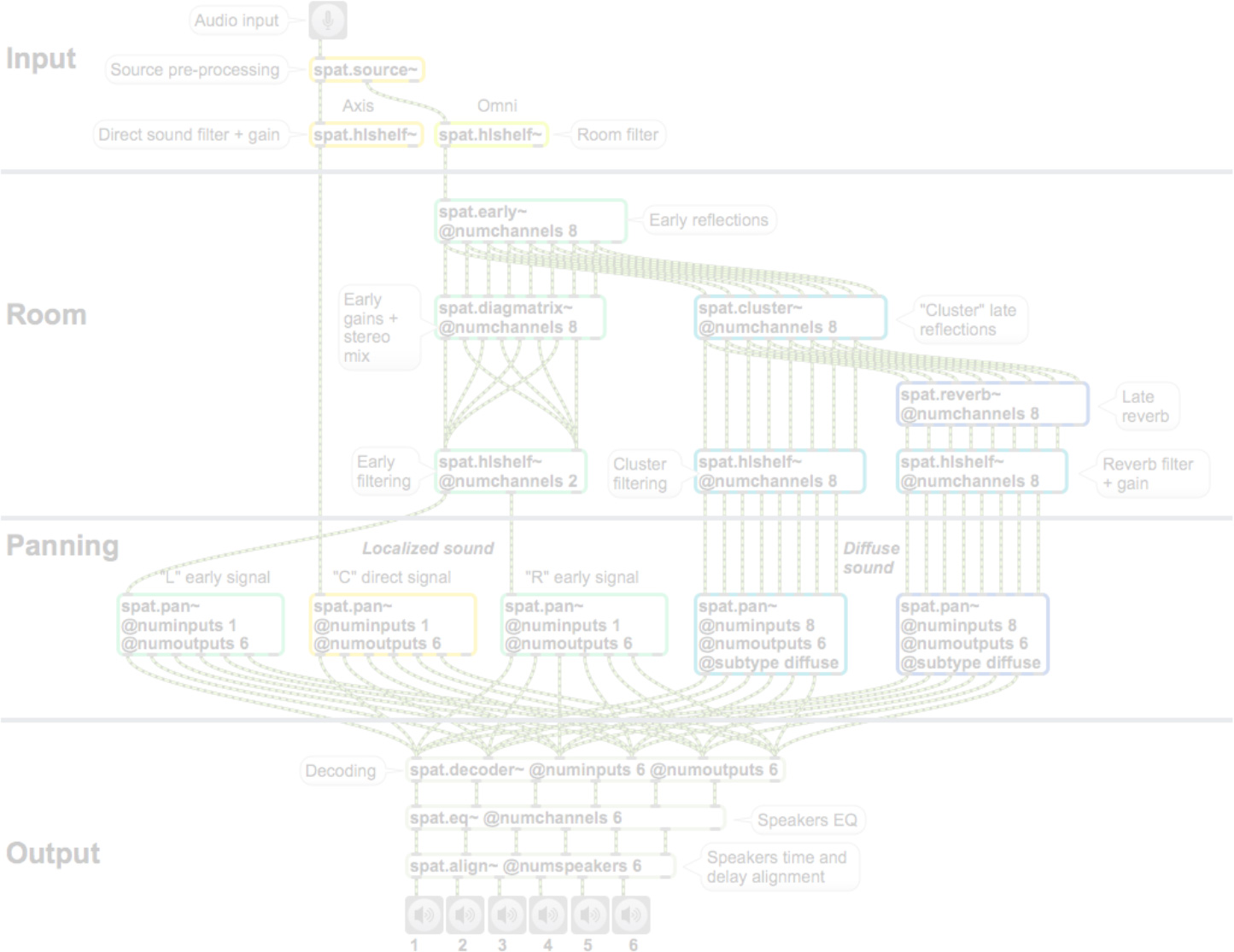
Figure 3. Global architecture of Spat∼. The “Input” module handles the source pre-processing such as filtering and simulating the Doppler effect and air absorption. The “Room” module generates the reverberation effect split in four temporal segments, each filtered independently. These four sections are later panned according to a simple space-time model: early reflections R1 “surround” the direct sound while sections R2 and R3 are spatially diffuse. Finally the “Output” module decodes or transcodes the signals according to the playback system, and it includes loudspeaker equalization and delay/gain alignment.
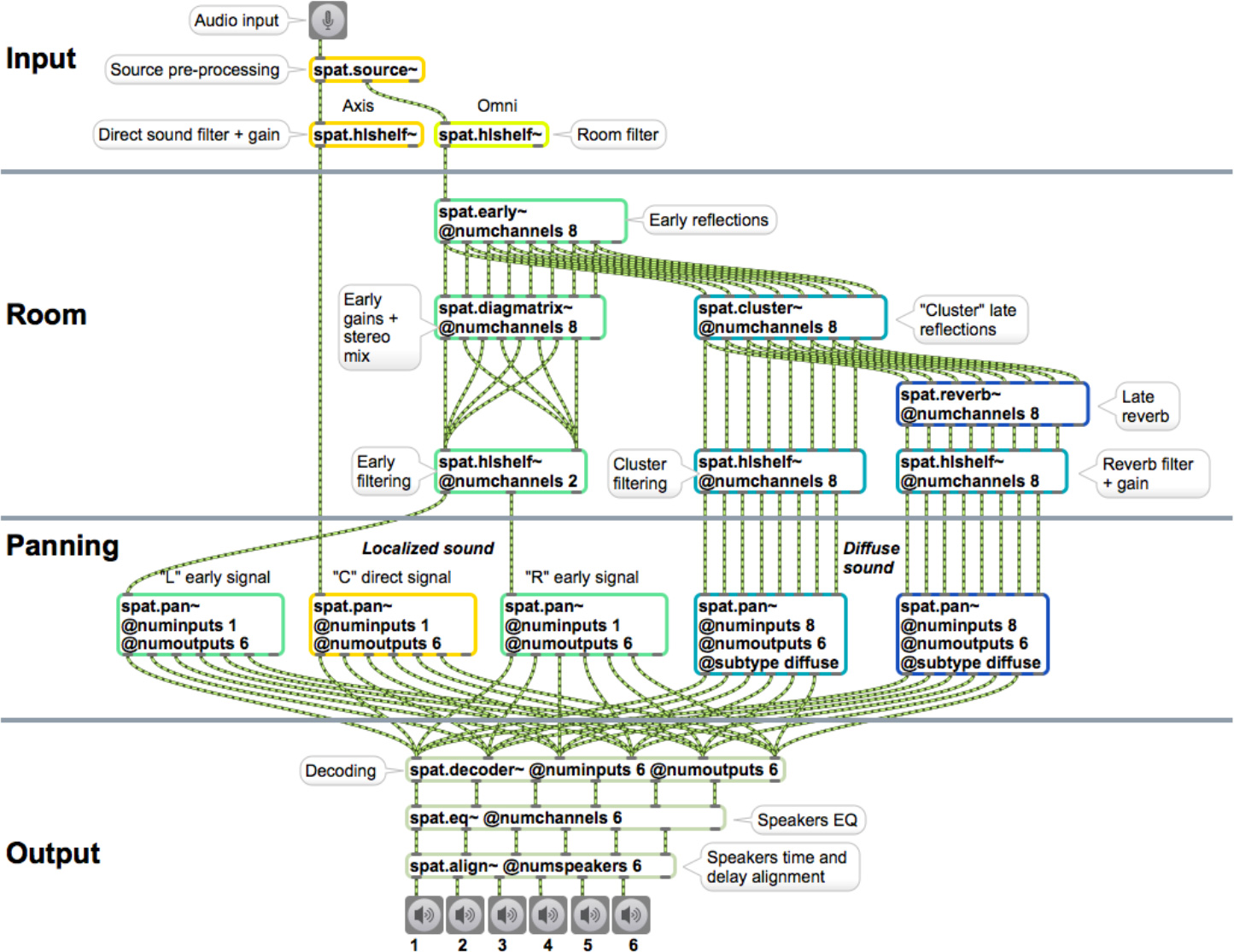
図3.Spat~の全体的なアーキテクチャ。「Input」モジュールは、フィルタやドップラー効果、空気吸収のシミュレーションなど、音源の事前処理を扱う。「Room」モジュールは、それぞれが独立してフィルタ処理される、4つの時間的な節に分けられるリバーブを生成する。これらの4つの節は、単純な時空間モデルにしたがって後にパンニングされる。初期反射R1は直接音を「取り囲」み、R2やR3は空間的に拡散される。最後に「Output」モジュールが、再生システムに従って信号をデコードもしくはトランスコードする。またラウドスピーカのイコライゼーションとディレイ/ゲインの調整を行う。
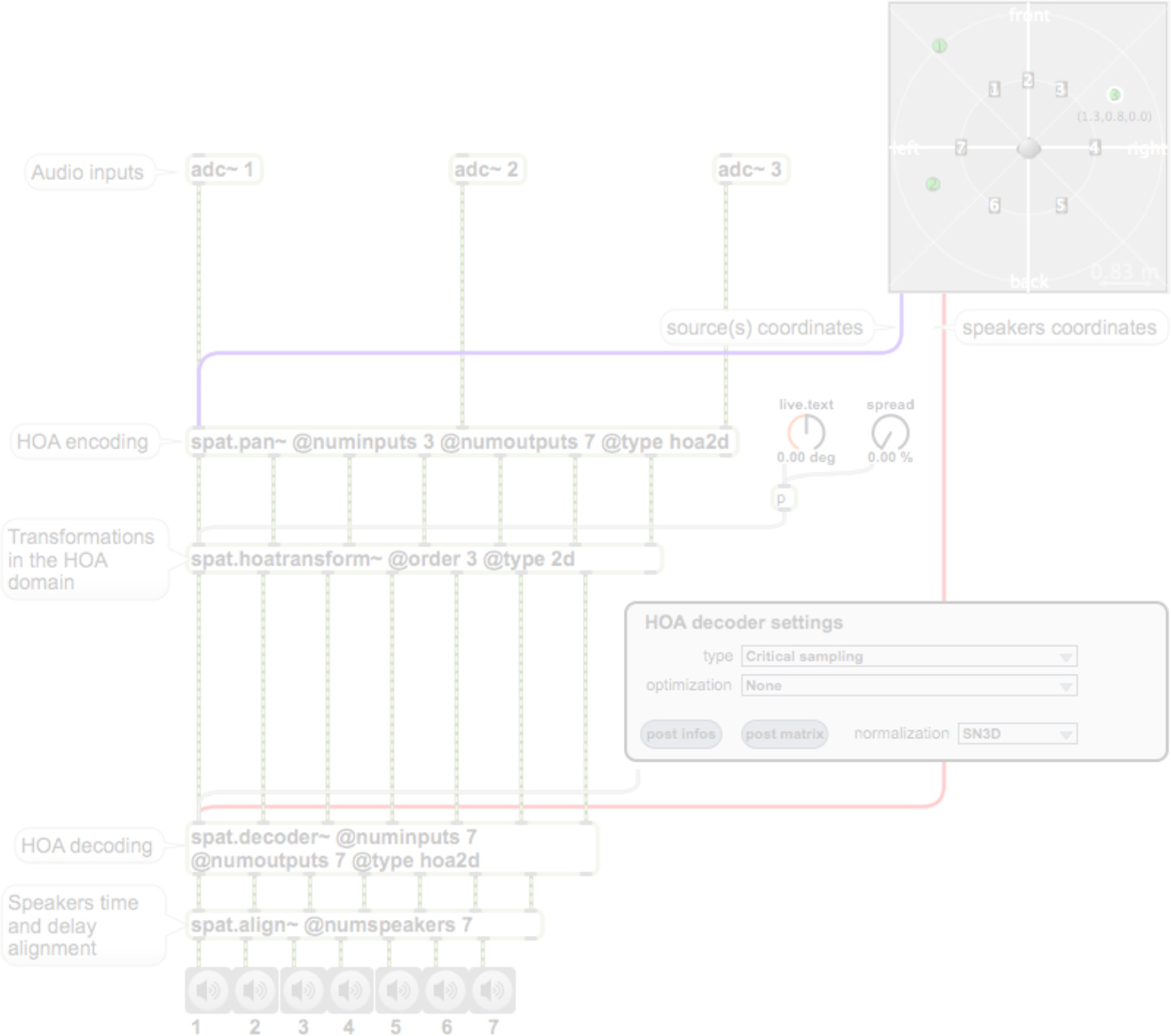
Figure 4. HOA workflow. In this example, three sources are encoded in 2D 3rd order Ambisonic then decoded over seven loudspeakers.
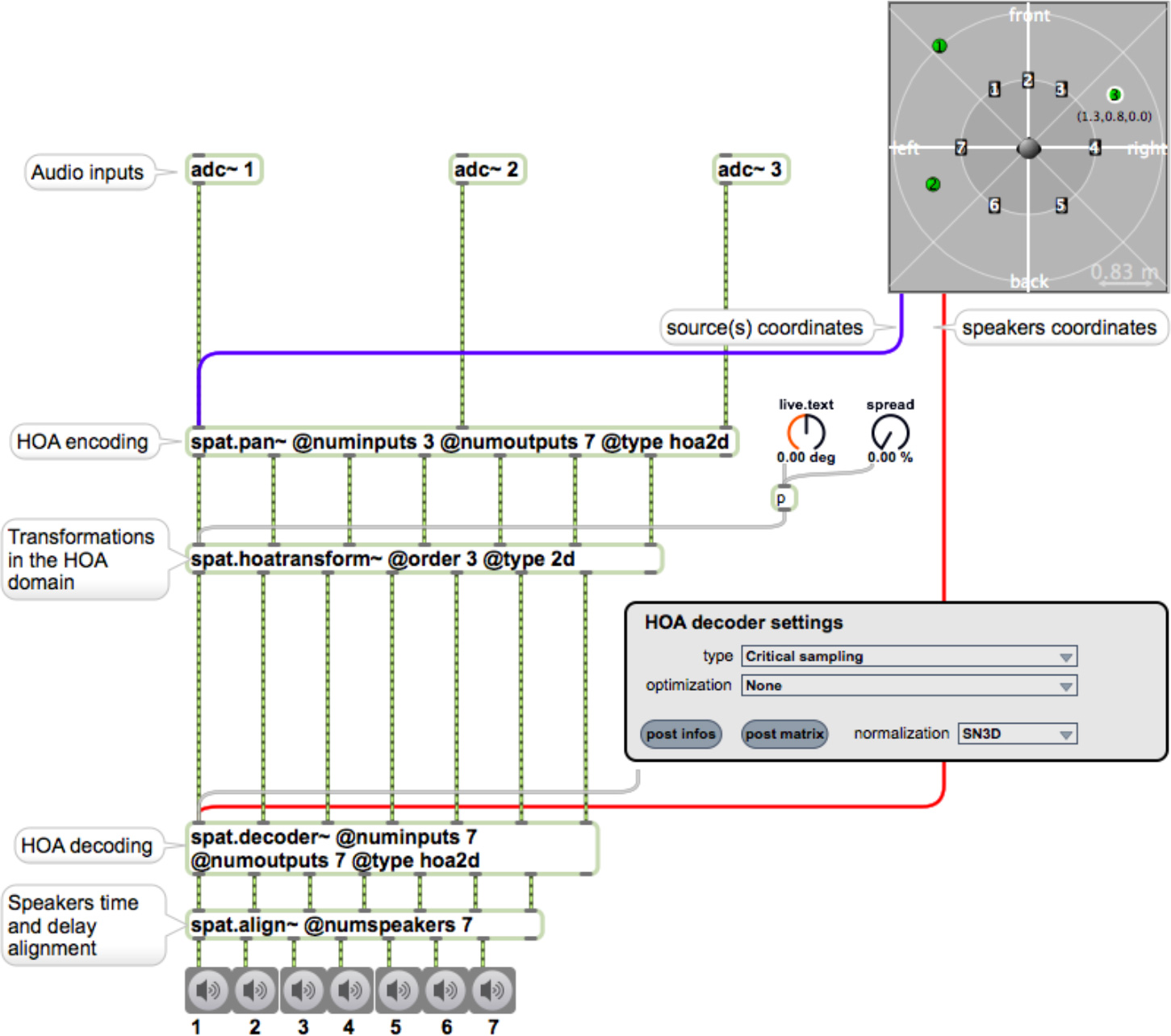
図4.HOAワークフロー。この例では、3つの音源を2D3次アンビソニックスにエンコードし、それから7つのラウドスピーカに対してデコードする。
*6 Interaural Level Differences
*6 Interaural Level Differences

Figure 5. TransPan control interface. Example with six sound sources.
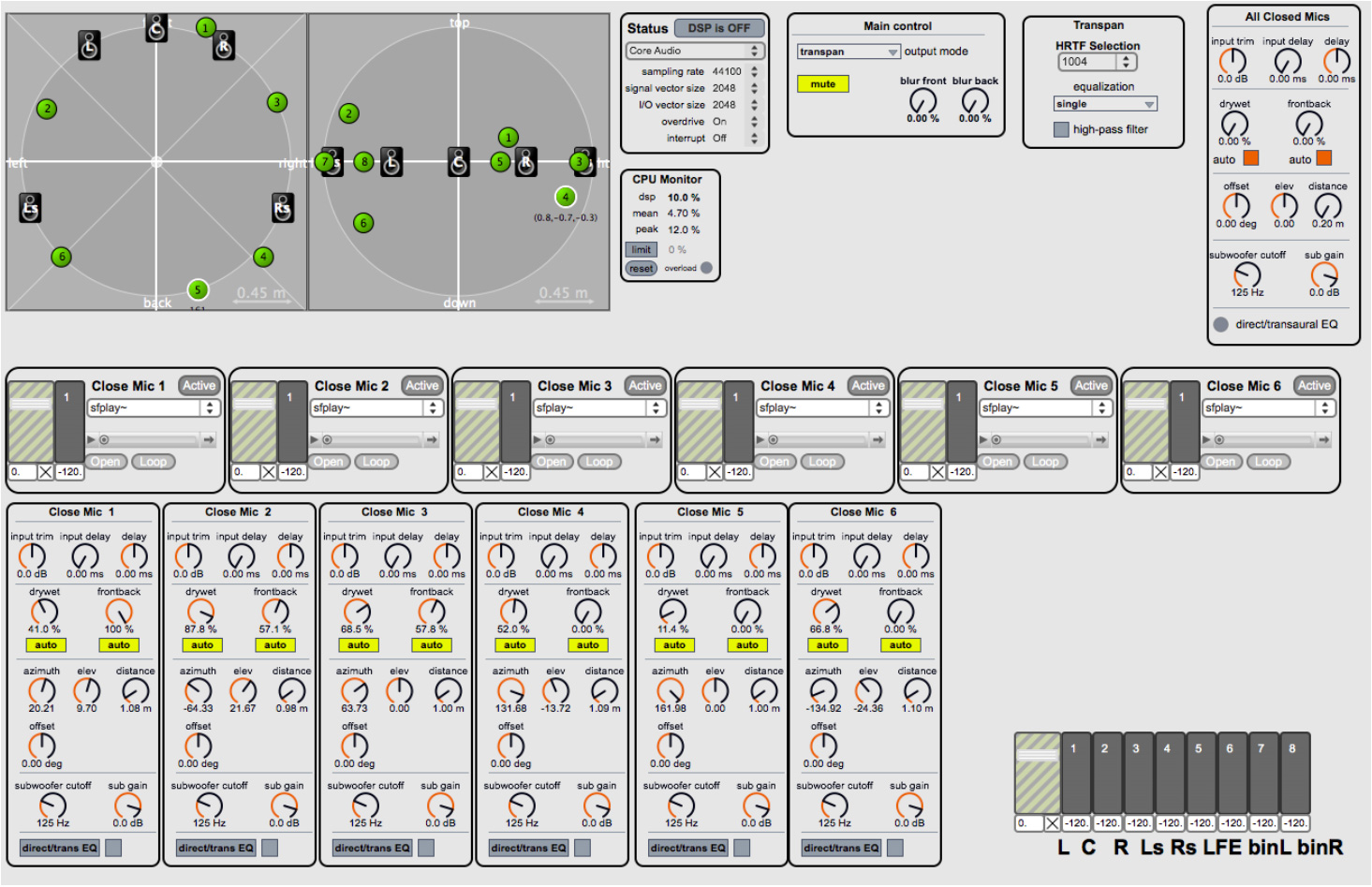
図5 TransPanの操作インターフェース。6つの音源による例。
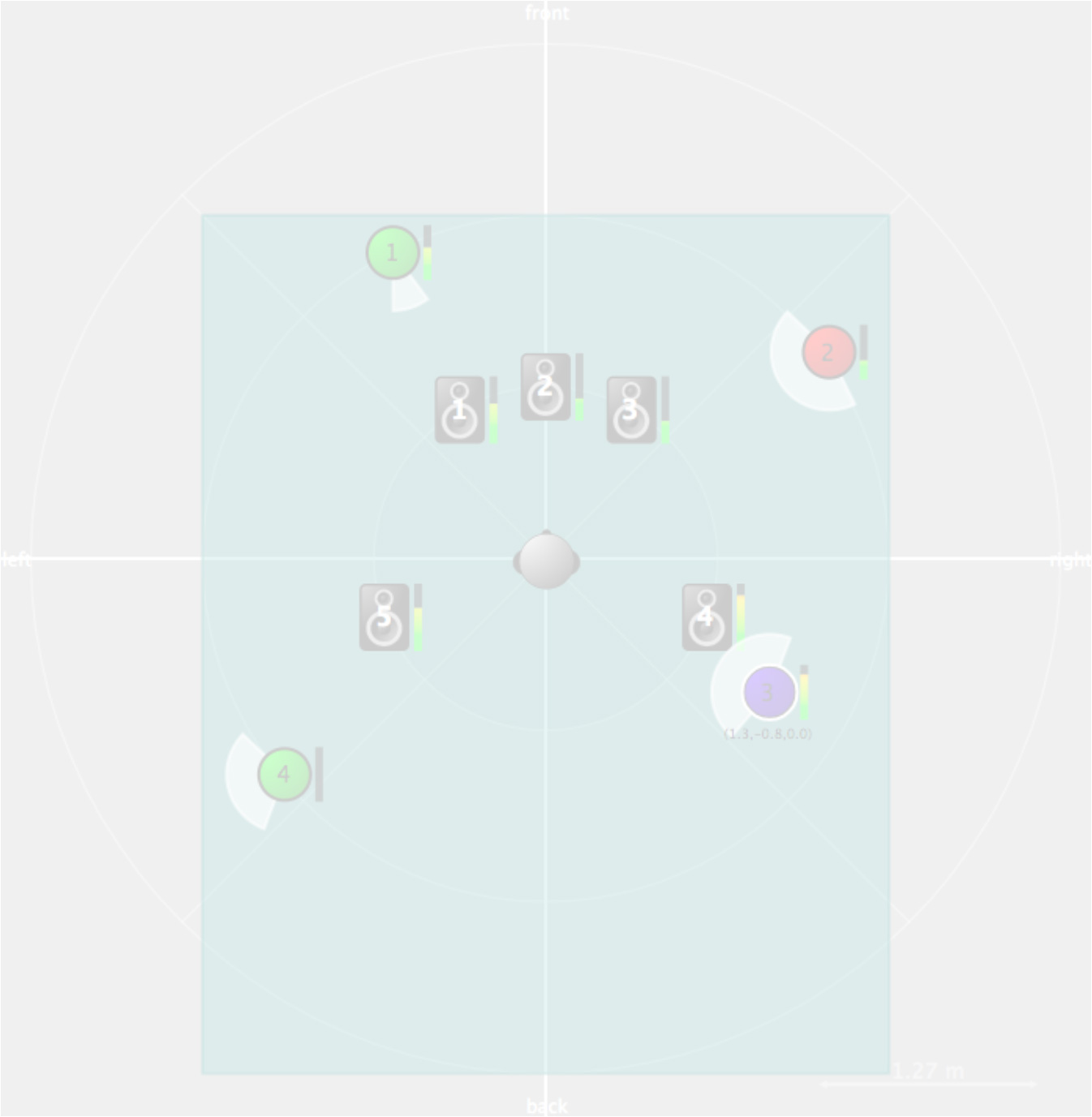
Figure 6. spat.viewer interface. Example with four sources, five loudspeakers and one listener, all in a virtual space. View from the top.
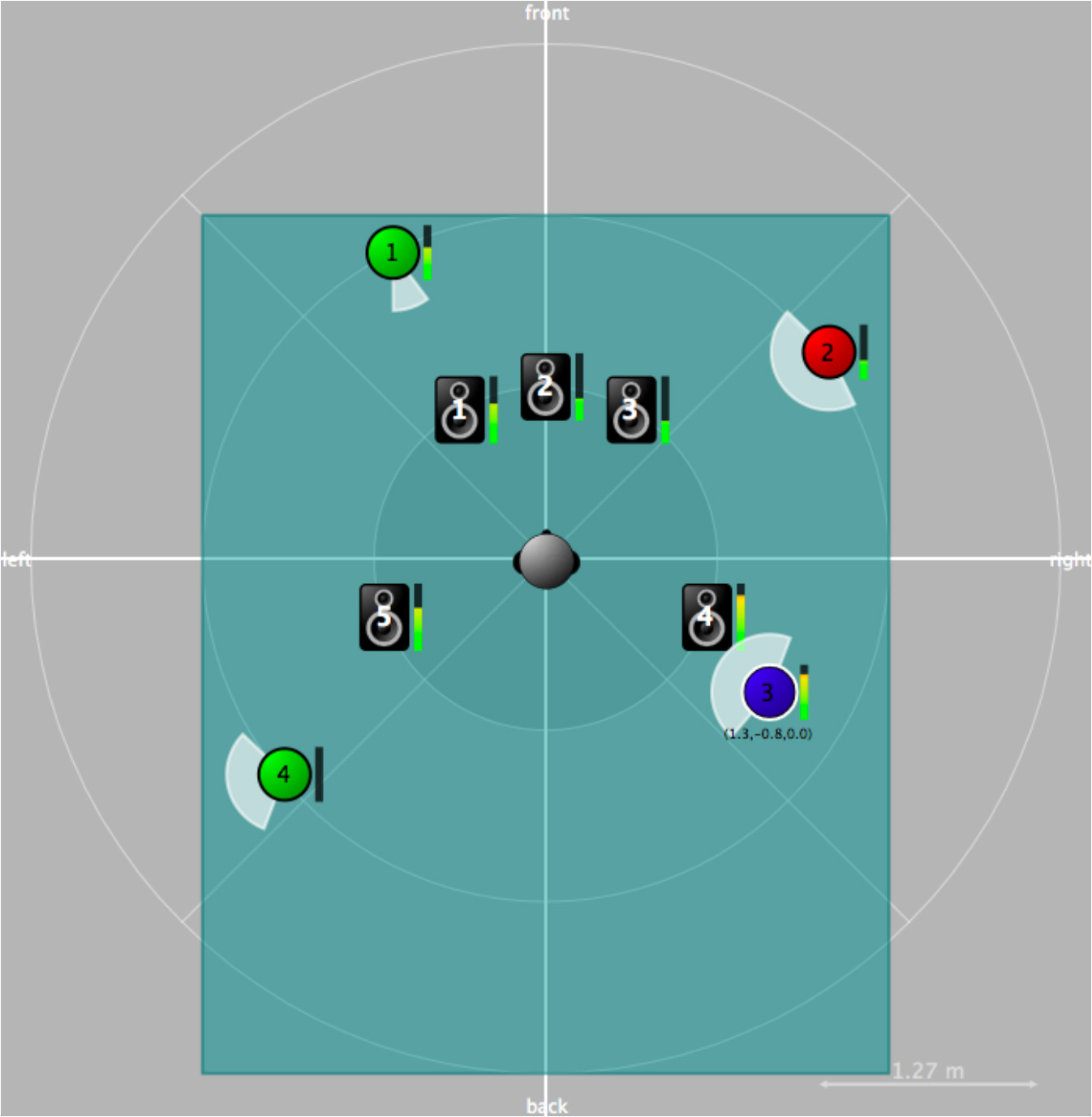
図6.spat.viewerインターフェース。4つの音源、5つのラウドスピーカと1人のリスナーが、すべてひとつの仮想空間にある例。頭上からの視点。
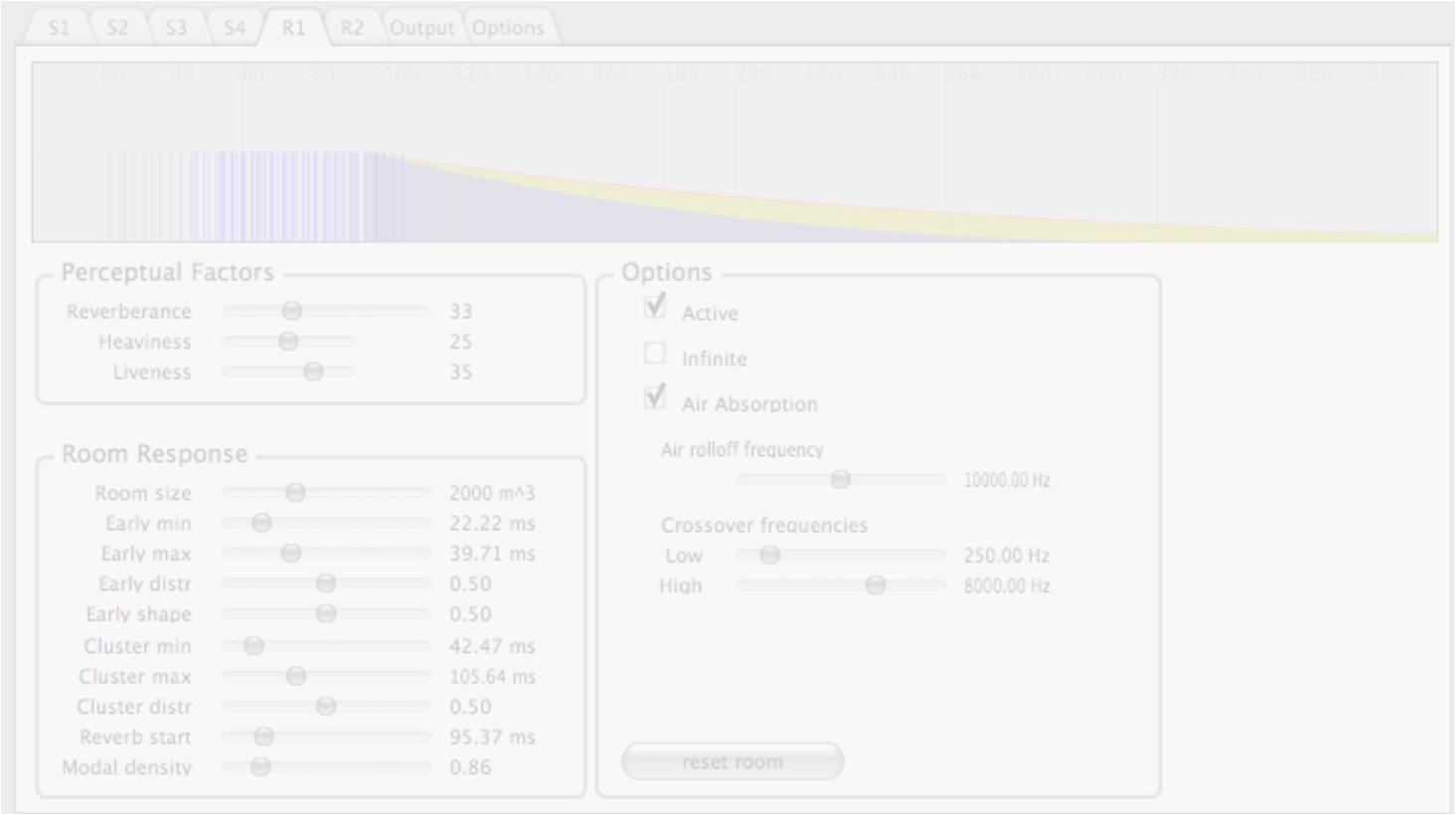
Figure 7. Screenshot of spat.oper: the reverb tab.
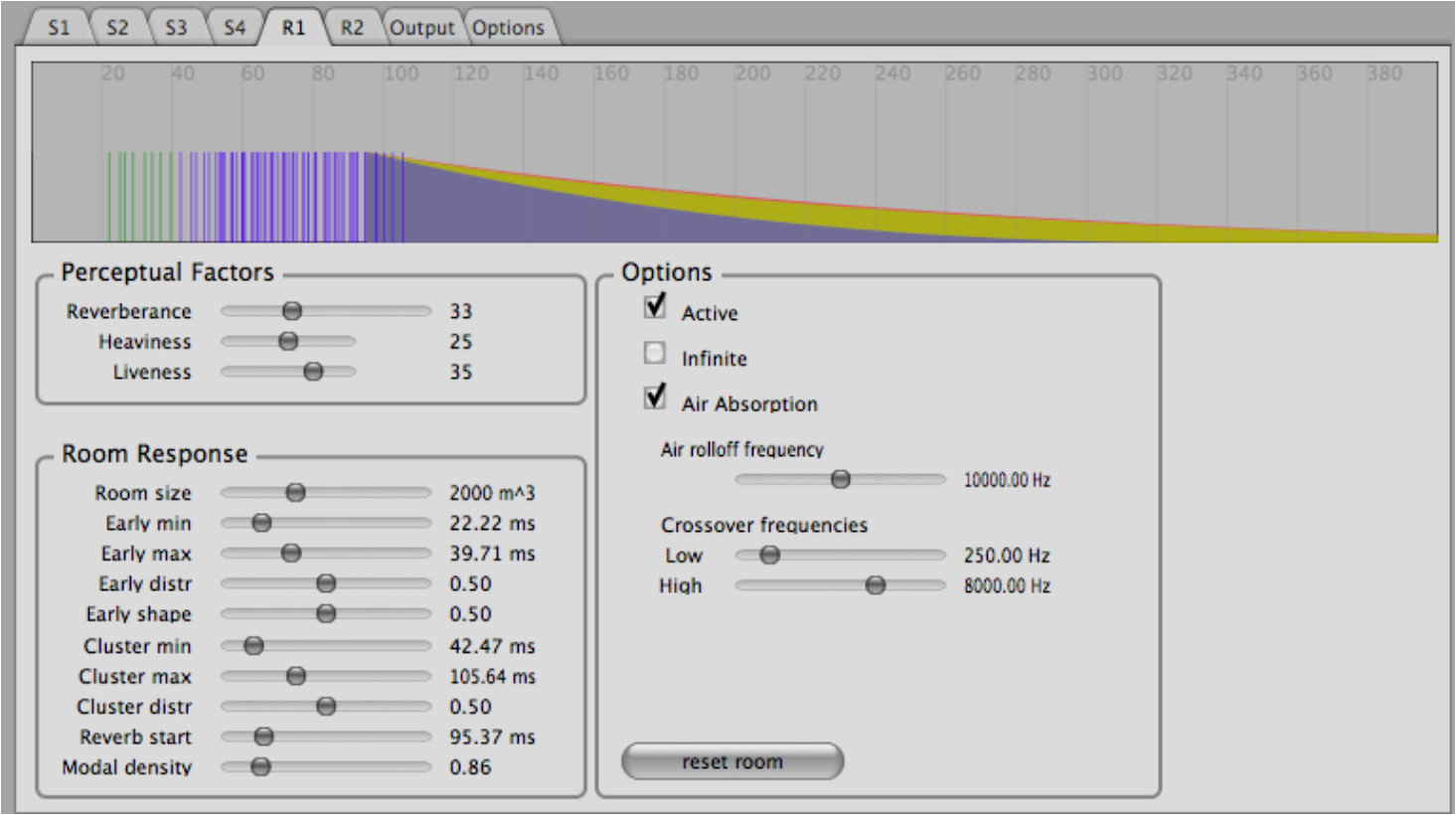
図7.spat.operのスクリーンショット:リバーブ・タブ
Figure 8. spat.oper: source tab. selection of the source tab. selection of the room tab. perceptual factors for the source. localization and radiation panel. direct sound filter. reverberated sound filter. visualization of the sound scene. other options.
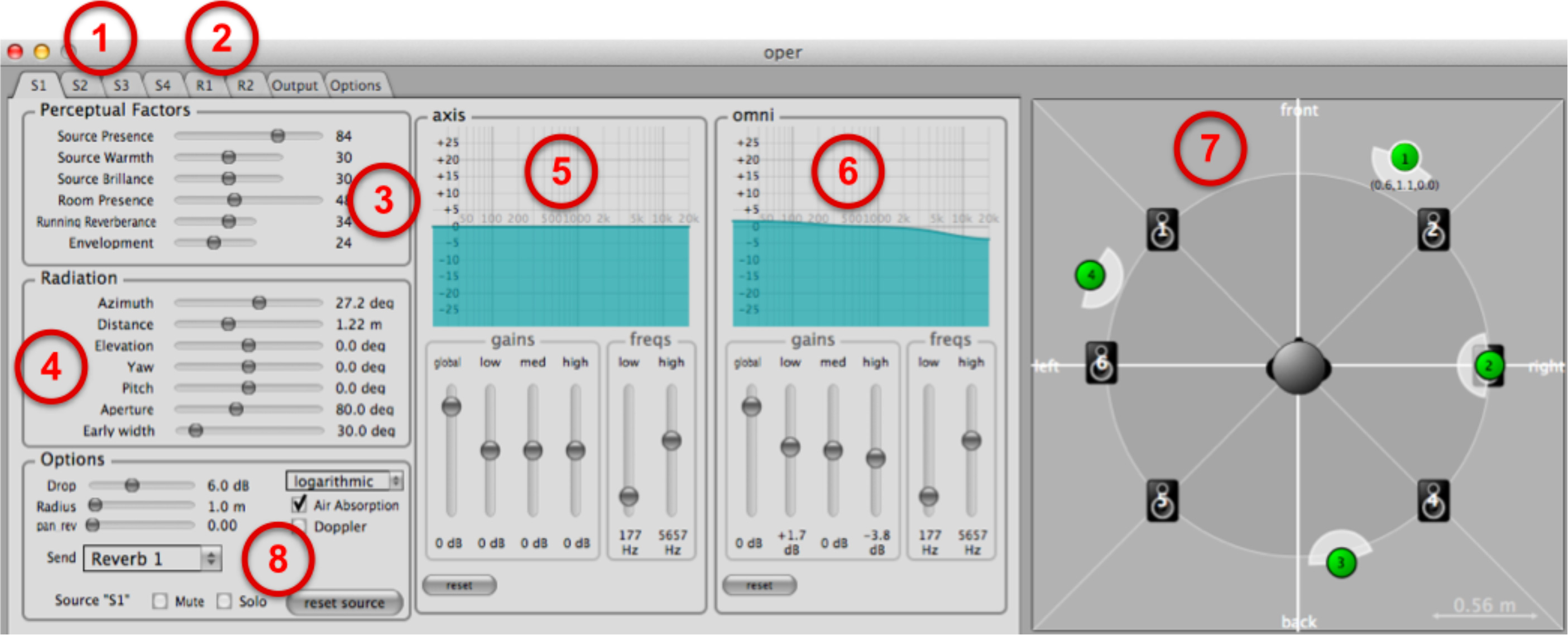
図8.spat.operの音源タブ:1.音源タブの選択、2.室内タブの選択、3.音源の知覚因子、4.位置と放射、5.直接音フィルタ、6.リバーブ音フィルタ、7.サウンド・シーンの視覚化、8.その他のオプション
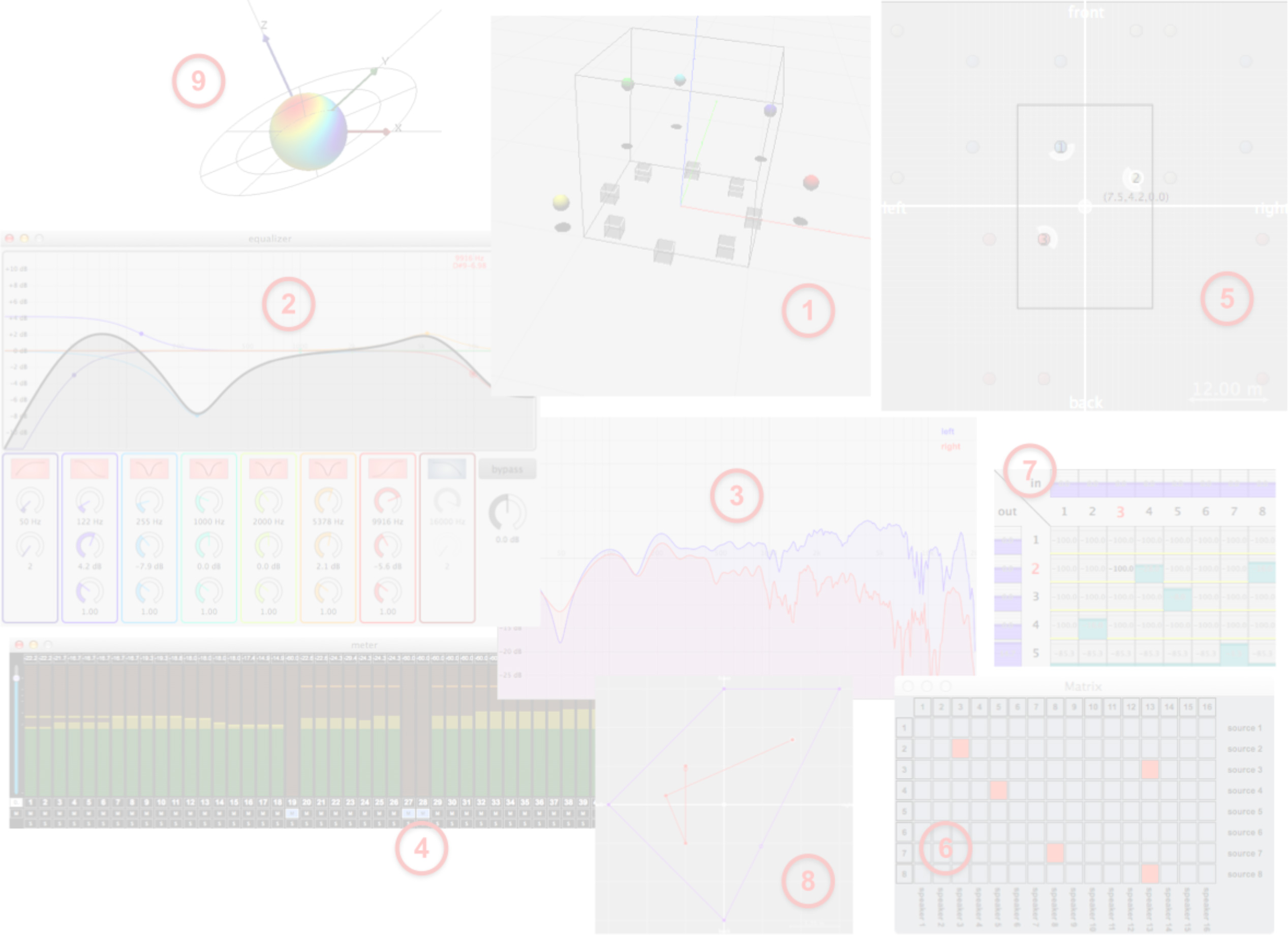
Figure 9. Several user interfaces included in Spat∼. Jitter interface for spat.viewer. parametric equalizer. HRTFs inspection (magnitude/phase responses). multichannel level meter. geometrical model with image sources. binary matrix. matrix control. authoring of spatial trajectories. 3D sound field visualization.
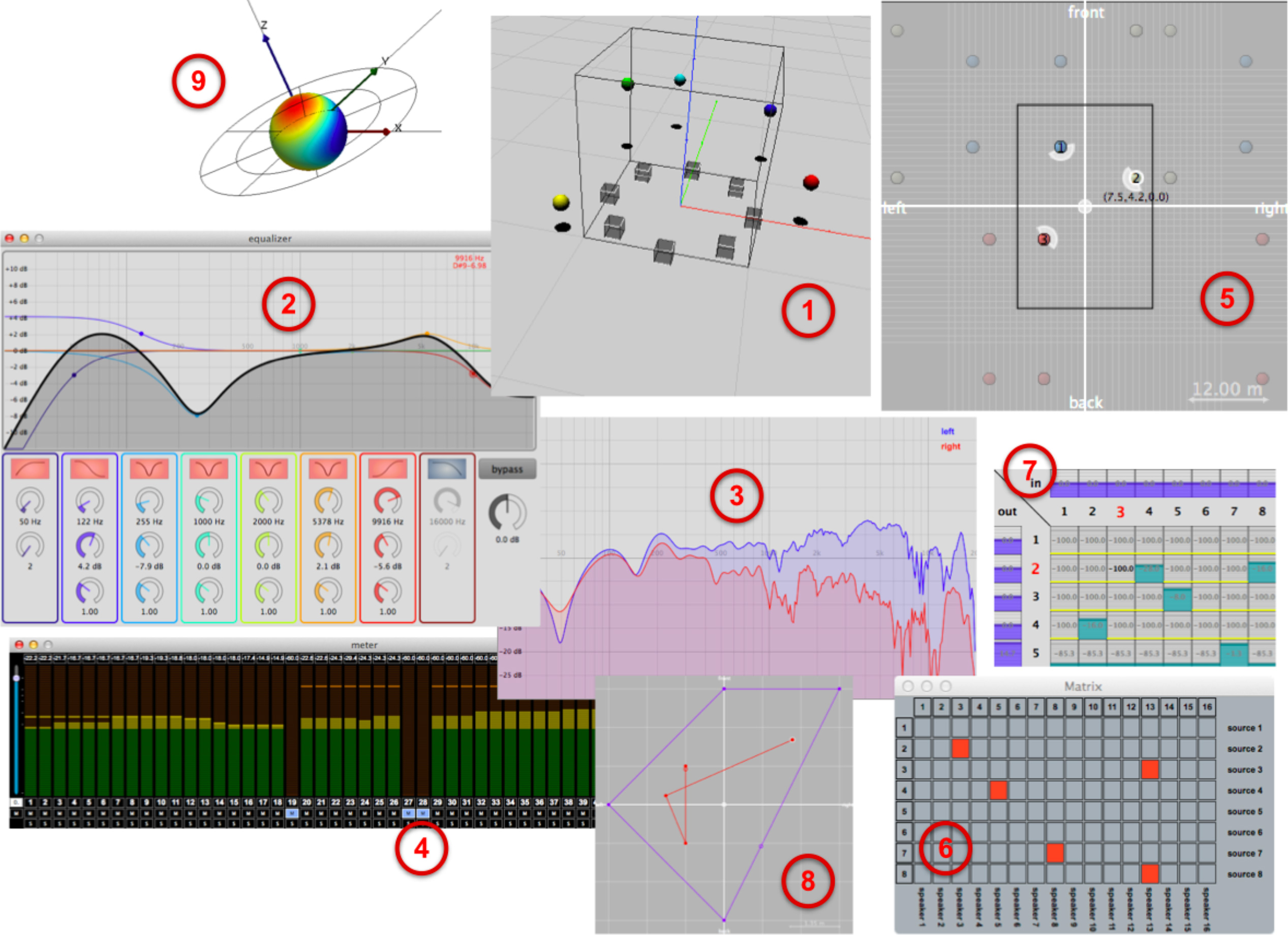
図9:Spat~に組み込まれたいくつかのユーザー・インターフェース。1.spat.viewerのためのJitterインターフェース、2.パラメトリック・イコライザ、3.HRTFインスペクション(強度/位相応答)、4.マルチチャンネル・レベル・メータ、5.幾何学モデルとイメージ・ソース、6.バイナリ・マトリクス、7.マトリクス・コントロール、8.空間移動のオーサリング、9.3D音場の視覚化
*10 http://sourceforge.net/projects/sofacoustics/
*11 http://hrtf.ircam.fr
*12 http://forumnet.ircam.fr/product/spat/
*10 http://sourceforge.net/projects/sofacoustics/
*11 http://hrtf.ircam.fr
*12 http://forumnet.ircam.fr/product/spat/
[2] J.-M. Jot, “Real-time spatial processing of sounds for music, multimedia and interactive human-computer interfaces,” ACM Multimedia Systems Journal (Special issue on Audio and Multimedia), vol. 7, no. 1, pp. 55 – 69, 1997.
[3] J.-M. Jot and O. Warusfel, “A Real-Time Spatial Sound Processor for Music and Virtual Reality Applications,” in Proceedings of the International Computer Music Conference, Banff, 1995.
[4] J.-P. Jullien, “Structured model for the representation and the control of room acoustic quality,” in Proceedings of the 15th International Congress on Acoustics (ICA), Trondheim, 1995, pp. 517 — 520.
[5] E. Kahle and J.-P. Jullien, “Subjective Listening Tests in Concert Halls: Methodology and Results,” in Proceedings of the 15th International Congress on Acoustics (ICA), Trondheim, June 1995, pp. 521 – 524.
[6] J. Bresson, C. Agon, and G. Assayag, “OpenMusic. Visual Programming Environment for Music Composition, Analysis and Research,” in Proceedings of ACM MultiMedia (OpenSource Software Competition), Scottsdale, 2011.
[7] J.-M. Jot, V. Larcher, and O. Warusfel, “Digital Signal Processing Issues in the Context of Binaural and Transaural Stereophony,” in Proceedings of the 98th Convention of the Audio Engineering Society, Paris, Feb. 1995.
[8] V. Pulkki, “Virtual Sound Source Positioning Using Vector Base Amplitude Panning,” Journal of the Audio Engineering Society, vol. 45, no. 6, pp. 456–466, June 1997.
[9] J.-M. Jot, V. Larcher, and J.-M. Pernaux, “A comparative study of 3-D audio encoding and rendering techniques,” in Proceedings of the 16th Audio Engineering Society International Conference on Spatial Sound Reproduction, Rovaniemi, 1999.
[10] T. Lossius, P. Balthazar, and T. de la Hogue, “DBAP - Distance-Based Amplitude Panning,” in Proceedings of the International Computer Music Conference, Montréal, 2009.
[11] R. Sadek and C. Kyriakakis, “A Novel Multichannel Panning Method for Standard and Arbitrary Loudspeaker Configurations,” in Proceedings of the 117th Audio Engineering Society Convention, San Francisco, 2004.
[12] J. Daniel, “Représentation de champs acoustiques, application à la transmission et à la reproduction de scènes sonores complexes dans un contexte multimédia,” Ph.D. dissertation, Université de Paris VI, 2001.
[13] M. Noisternig, T. Carpentier, and O. Warusfel, “Espro 2.0 – Implementation of a surrounding 350-loudspeaker array for sound field reproduction.” in Proceedings of the 25th Audio Engineering Society UK Conference, 2012.
[14] J. Daniel and S. Moreau, “Further Study of Sound Field Coding with Higher Order Ambisonics,” in Proceedings of the 116th Audio Engineering Society Convention, Berlin, 2004.
[15] F. Zotter, H. Pomberger, and M. Noisternig, “Energy-Preserving Ambisonic Decoding,” Acta Acustica united with Acustica, vol. 98, 2012.
[16] M. Pollow, K.-V. Nguyen, O. Warusfel, T. Carpentier, M. Müller-Trapet, M. Vorländer, and M. Noisternig, “Calculation of Head-Related Transfer Functions for Arbitrary Field Points Using Spherical Harmonics Decomposition,” Acta Acustica united with Acustica, vol. 98, 2012.
[17] R. O. Duda and W. L. Martens, “Range dependence of the response of a spherical head model,” Journal of the Acoustical Society of America, vol. 104, no. 5, pp. 3048– 3058, 1998.
[18] D. Romblom and B. Cook, “Near-Field Compensation for HRTF Processing,” in Proceedings of the 125th Audio Engineering Society Convention, San Francisco, 2008.
[19] A. Baskind, T. Carpentier, M. Noisternig, O. Warusfel, and J.-M. Lyzwa, “Binaural and transaural spatialization techniques in multichannel 5.1 production,” in Proceedings of the 27th Tonmeistertagung – VDT International Convention, Köln, November 2012.
[20] W. G. Gardner, “Efficient Convolution without Input-Output Delay,” in Proceedings of the 97th Convention of the Audio Engineering Society, San Francisco, 1994.
[21] M.Noisternig, T.Carpentier, and O.Warusfel,“Perceptual Control of Convolution Based Room Simulators,” in The Acoustics 2012 Hong Kong Conference, Hong Kong, 2012.
[22] A. Farina, “Simultaneous measurement of impulse response and distortion with a swept-sine technique,” in Proceedings of the 108th Convention of the Audio Engineering Society, Paris, 2000.
[23] J.-M. Jot, L. Cerveau, and O. Warusfel, “Analysis and Synthesis of Room Reverberation Based on a Statistical Time- Frequency Model,” in Proceedings of the 103rd Convention of the Audio Engineering Society, New York, 1997.
[24] T. Carpentier, M. Noisternig, and O. Warusfel, “Hybrid Reverberation Processor with Perceptual Control,” in Pro- ceedings of the 17th Int. Conference on Digital Audio Effects (DAFx-14), Erlangen, Sept. 2014.
[25] H. Møller, “Fundamentals of Binaural Technology,” Applied Acoustics, vol. 36, pp. 171 – 218, 1992.
[26] P. Majdak, Y. Iwaya, T. Carpentier, R. Nicol, M. Parmen- tier, A. Roginska, Y. Suzuki, K. Watanabe, H. Wierstorf, H. Ziegelwanger, and M. Noisternig, “Spatially Oriented Format for Acoustics: A Data Exchange Format Representing Head-Related Transfer Functions,” in Proceedings of the 134rd Convention of the Audio Engineering Society, Roma, May 2013.
[2] J.-M. Jot, “Real-time spatial processing of sounds for music, multimedia and interactive human-computer interfaces,” ACM Multimedia Systems Journal (Special issue on Audio and Multimedia), vol. 7, no. 1, pp. 55 – 69, 1997.
[3] J.-M. Jot and O. Warusfel, “A Real-Time Spatial Sound Processor for Music and Virtual Reality Applications,” in Proceedings of the International Computer Music Conference, Banff, 1995.
[4] J.-P. Jullien, “Structured model for the representation and the control of room acoustic quality,” in Proceedings of the 15th International Congress on Acoustics (ICA), Trondheim, 1995, pp. 517 — 520.
[5] E. Kahle and J.-P. Jullien, “Subjective Listening Tests in Concert Halls: Methodology and Results,” in Proceedings of the 15th International Congress on Acoustics (ICA), Trondheim, June 1995, pp. 521 – 524.
[6] J. Bresson, C. Agon, and G. Assayag, “OpenMusic. Visual Programming Environment for Music Composition, Analysis and Research,” in Proceedings of ACM MultiMedia (OpenSource Software Competition), Scottsdale, 2011.
[7] J.-M. Jot, V. Larcher, and O. Warusfel, “Digital Signal Processing Issues in the Context of Binaural and Transaural Stereophony,” in Proceedings of the 98th Convention of the Audio Engineering Society, Paris, Feb. 1995.
[8] V. Pulkki, “Virtual Sound Source Positioning Using Vector Base Amplitude Panning,” Journal of the Audio Engineering Society, vol. 45, no. 6, pp. 456–466, June 1997.
[9] J.-M. Jot, V. Larcher, and J.-M. Pernaux, “A comparative study of 3-D audio encoding and rendering techniques,” in Proceedings of the 16th Audio Engineering Society International Conference on Spatial Sound Reproduction, Rovaniemi, 1999.
[10] T. Lossius, P. Balthazar, and T. de la Hogue, “DBAP - Distance-Based Amplitude Panning,” in Proceedings of the International Computer Music Conference, Montréal, 2009.
[11] R. Sadek and C. Kyriakakis, “A Novel Multichannel Panning Method for Standard and Arbitrary Loudspeaker Configurations,” in Proceedings of the 117th Audio Engineering Society Convention, San Francisco, 2004.
[12] J. Daniel, “Représentation de champs acoustiques, application à la transmission et à la reproduction de scènes sonores complexes dans un contexte multimédia,” Ph.D. dissertation, Université de Paris VI, 2001.
[13] M. Noisternig, T. Carpentier, and O. Warusfel, “Espro 2.0 – Implementation of a surrounding 350-loudspeaker array for sound field reproduction.” in Proceedings of the 25th Audio Engineering Society UK Conference, 2012.
[14] J. Daniel and S. Moreau, “Further Study of Sound Field Coding with Higher Order Ambisonics,” in Proceedings of the 116th Audio Engineering Society Convention, Berlin, 2004.
[15] F. Zotter, H. Pomberger, and M. Noisternig, “Energy-Preserving Ambisonic Decoding,” Acta Acustica united with Acustica, vol. 98, 2012.
[16] M. Pollow, K.-V. Nguyen, O. Warusfel, T. Carpentier, M. Müller-Trapet, M. Vorländer, and M. Noisternig, “Calculation of Head-Related Transfer Functions for Arbitrary Field Points Using Spherical Harmonics Decomposition,” Acta Acustica united with Acustica, vol. 98, 2012.
[17] R. O. Duda and W. L. Martens, “Range dependence of the response of a spherical head model,” Journal of the Acoustical Society of America, vol. 104, no. 5, pp. 3048– 3058, 1998.
[18] D. Romblom and B. Cook, “Near-Field Compensation for HRTF Processing,” in Proceedings of the 125th Audio Engineering Society Convention, San Francisco, 2008.
[19] A. Baskind, T. Carpentier, M. Noisternig, O. Warusfel, and J.-M. Lyzwa, “Binaural and transaural spatialization techniques in multichannel 5.1 production,” in Proceedings of the 27th Tonmeistertagung – VDT International Convention, Köln, November 2012.
[20] W. G. Gardner, “Efficient Convolution without Input-Output Delay,” in Proceedings of the 97th Convention of the Audio Engineering Society, San Francisco, 1994.
[21] M.Noisternig, T.Carpentier, and O.Warusfel,“Perceptual Control of Convolution Based Room Simulators,” in The Acoustics 2012 Hong Kong Conference, Hong Kong, 2012.
[22] A. Farina, “Simultaneous measurement of impulse response and distortion with a swept-sine technique,” in Proceedings of the 108th Convention of the Audio Engineering Society, Paris, 2000.
[23] J.-M. Jot, L. Cerveau, and O. Warusfel, “Analysis and Synthesis of Room Reverberation Based on a Statistical Time- Frequency Model,” in Proceedings of the 103rd Convention of the Audio Engineering Society, New York, 1997.
[24] T. Carpentier, M. Noisternig, and O. Warusfel, “Hybrid Reverberation Processor with Perceptual Control,” in Pro- ceedings of the 17th Int. Conference on Digital Audio Effects (DAFx-14), Erlangen, Sept. 2014.
[25] H. Møller, “Fundamentals of Binaural Technology,” Applied Acoustics, vol. 36, pp. 171 – 218, 1992.
[26] P. Majdak, Y. Iwaya, T. Carpentier, R. Nicol, M. Parmen- tier, A. Roginska, Y. Suzuki, K. Watanabe, H. Wierstorf, H. Ziegelwanger, and M. Noisternig, “Spatially Oriented Format for Acoustics: A Data Exchange Format Representing Head-Related Transfer Functions,” in Proceedings of the 134rd Convention of the Audio Engineering Society, Roma, May 2013.